
Enhancing Automation Testing with AI and TensorFlow
Automation testing has become a vital part of software development, ensuring rapid and consistent validation of applications. However, traditional automation frameworks often fall short in dynamic environments where locators break due to frequent UI changes. This article introduces a robust AI-powered solution for automation testing, leveraging TensorFlow, Pandas, NumPy, and Selenium.
1. Why Automation Testing?
Automation testing accelerates repetitive testing tasks, reduces human error, and improves efficiency in software development lifecycles. It ensures faster feedback, allowing teams to focus on innovation while maintaining software quality.
2. Why Add AI or Machine Learning to Automation Testing?
Dynamic web applications frequently change their structure, causing traditional locators (id, class, etc.) to fail. AI introduces adaptability, enabling:
- Dynamic Locator Prediction: AI predicts the most stable locator based on element attributes.
- Self-Healing Scripts: Automatically switch to alternative locators if the primary one fails.
- Reduced Maintenance: Minimizes the need for manual updates in test scripts.
3. What Kind of AI Is Integrated?
This project integrates a machine learning model built with TensorFlow. The model:
- Predicts Element Type: Identifies whether an element is a
button,input,link, etc. - Determines the Best Locator: Predicts the most reliable locator (
id,class,name, etc.) for interaction. This combination ensures robust and adaptable test automation.
4. Libraries Used to Build the Code
The project uses the following libraries:
- TensorFlow: For building and training the machine learning model.
- Pandas: To preprocess and manipulate the dataset.
- NumPy: For numerical computations and feature transformations.
- Selenium: To interact with the web browser and perform actions.
- scikit-learn: For scaling and splitting the dataset.
- joblib: For saving and loading preprocessing tools like scalers.
5. Project Structure
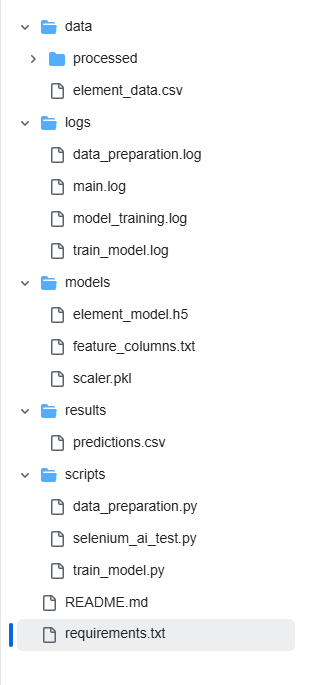
6. Dataset Used
The dataset (element_data.csv) includes attributes for web elements that serve as input features for the model. Key attributes:
id,class,text,tag,value,type,name: Element attributes for locating elements.label: Element type (button,input, etc.).locator: Preferred locator type (id,class, etc.).
Example Dataset Row:
id,class,text,tag,value,type,name,label,locator
name-field,input-class,Name,input,Name,text,name,input,name
7. What Kind of Processed Data Is Available?
Processed data includes:
- One-Hot Encoded Features: For categorical attributes like
id,class, andtype. - Scaled Features: To normalize numerical values for model compatibility.
Why Process Data? Processing ensures consistency, removes inconsistencies, and prepares data for machine learning by converting it into a usable numerical format.
8. Why Hybrid Encoding?
Hybrid encoding ensures that all possible locator types (id, class, name, etc.) are represented in the dataset, even if some are missing. This approach guarantees consistent feature dimensions and allows the model to handle various locators during runtime.
9. Which Model Was Used and How Was It Trained?
This project uses a supervised machine learning model built with TensorFlow to predict element types and locators for automation testing. The model architecture is designed to handle multi-class classification tasks effectively, ensuring robustness and adaptability.
Model Architecture
- Input Layer:
- The input layer accepts the preprocessed features, such as
id,class,text,value,type, andname. These features are numerical values obtained after one-hot encoding and scaling. - This layer provides a numerical representation of web element attributes to the model.
- The input layer accepts the preprocessed features, such as
- Hidden Layers:
- The model includes two dense (fully connected) layers with 128 and 64 neurons, respectively, using ReLU (Rectified Linear Unit) activation.
- ReLU helps in learning complex patterns by introducing non-linearity into the model, enabling it to capture relationships between input features.
- Output Layers:
- Element Type Prediction:
- A softmax activation layer predicts the type of the element (
button,input,link, etc.). - The output is a probability distribution, and the element type with the highest probability is selected.
- A softmax activation layer predicts the type of the element (
- Locator Prediction:
- Another softmax activation layer predicts the most stable locator (
id,class,name, etc.). - The output is similar to the element type prediction, providing a probability distribution across locators.
- Another softmax activation layer predicts the most stable locator (
- Element Type Prediction:
Training Steps
- Data Splitting:
- The dataset is split into training and testing subsets using an 80-20 split.
- This ensures the model is evaluated on unseen data, reducing overfitting.
- Feature Scaling:
- Before training, all numerical inputs are normalized using
StandardScalerto ensure consistent data distribution. - Scaling converts features into a standard range, improving the convergence of the model.
- Before training, all numerical inputs are normalized using
- Model Training:
- Loss Function:
categorical_crossentropyis used for both element type and locator predictions.- It measures the difference between the predicted probability distribution and the actual labels.
- Optimizer:
- The Adam optimizer (Adaptive Moment Estimation) is chosen for its efficiency and ability to handle sparse gradients.
- Adam dynamically adjusts the learning rate during training, improving convergence.
- Metrics:
- Accuracy is used to evaluate the model’s performance for both tasks.
- It measures the proportion of correct predictions in the test set.
- Loss Function:
- Model Saving:
- After training, the model is saved as
element_model.h5. - This file contains the trained weights and architecture, allowing it to be reloaded for inference during runtime.
- After training, the model is saved as
Additional Insights
- Multi-Output Design:
- The model simultaneously predicts two outputs: the element type and the locator type. This multi-task approach improves efficiency and ensures that both predictions are aligned with the input features.
- Batch Training:
- Training is performed in mini-batches of 32 samples over multiple epochs (iterations), optimizing the model iteratively for better accuracy.
- Validation:
- A validation dataset (from the test split) is used during training to monitor the model’s performance and prevent overfitting.
By following these steps, the model achieves high accuracy in predicting element types and locators, making it reliable for automation testing in dynamic web environments. The robust design ensures it can generalize well across different datasets and applications.
10. Main Execution Code
The following code combines the trained AI model with Selenium to dynamically locate and interact with web elements:
from selenium import webdriver
from selenium.webdriver.common.by import By
import tensorflow as tf
import pandas as pd
import joblib
import logging
import time
logging.basicConfig(filename='logs/main.log', level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s')
MODEL_PATH = 'models/element_model.h5'
FEATURE_COLUMNS_PATH = 'models/feature_columns.txt'
SCALER_PATH = 'models/scaler.pkl'
def load_model_and_scaler(model_path, feature_columns_path, scaler_path):
model = tf.keras.models.load_model(model_path)
with open(feature_columns_path, 'r') as f:
feature_columns = f.read().splitlines()
scaler = joblib.load(scaler_path)
return model, scaler, feature_columns
def preprocess_input(features, scaler, feature_columns):
input_df = pd.DataFrame([features])
input_encoded = pd.get_dummies(input_df, columns=['id', 'class', 'text', 'tag', 'type', 'value'])
input_encoded = input_encoded.reindex(columns=feature_columns, fill_value=0)
input_scaled = scaler.transform(input_encoded)
return input_scaled
def predict_and_act(driver, model, scaler, feature_columns):
"""
Predict element type and locator type, validate predictions, and perform an action using Selenium.
"""
# Example input features
element_features = {
'id': 'email-field',
'class': 'email-class',
'text': 'Email',
'tag': 'input',
'value': '',
'type': '',
'name': 'name'
}
# Preprocess input features
input_scaled = preprocess_input(element_features, scaler, feature_columns)
# Predict element type and locator type
predictions = model.predict(input_scaled)
element_type_probs = predictions[0][0] # Extract probabilities for element type
locator_type_probs = predictions[1][0] # Extract probabilities for locator type
# Define maps
label_map = {0: 'button', 1: 'input', 2: 'link', 3: 'select', 4: 'password'}
locator_map = {0: 'id', 1: 'class', 2: 'text', 3: 'value', 4: 'type', 5: 'name'}
# Extract predictions separately
predicted_type = label_map[int(element_type_probs.argmax())]
predicted_locator_order = [
locator_map[int(i)]
for i in locator_type_probs.argsort()[::-1]
if element_features.get(locator_map[int(i)], '') # Only include non-blank locators
]
logging.info(f"Predicted Element Type: {predicted_type}")
logging.info(f"Predicted Locator Priority: {predicted_locator_order}")
# Validate predicted type based on HTML tag
if predicted_type != 'input' and element_features['tag'] == 'input':
logging.warning(f"Predicted type '{predicted_type}' corrected to 'input' based on HTML tag.")
predicted_type = 'input'
# Locate and interact with the element
element = None
for locator in predicted_locator_order:
try:
if locator == 'id':
element = driver.find_element(By.ID, element_features['id'])
elif locator == 'class':
element = driver.find_element(By.CLASS_NAME, element_features['class'])
elif locator == 'text':
element = driver.find_element(By.XPATH, f"//*[text()='{element_features['text']}']")
elif locator == 'value':
element = driver.find_element(By.XPATH, f"//*[@value='{element_features['value']}']")
elif locator == 'type':
element = driver.find_element(By.XPATH, f"//*[@type='{element_features['type']}']")
elif locator == 'name':
element = driver.find_element(By.NAME, element_features['name'])
if element:
logging.info(f"Element located using {locator}.")
break
except Exception as e:
logging.warning(f"Failed to locate element using {locator}: {e}")
if not element:
raise ValueError("Unable to locate element with any available locators.")
# Perform action based on predicted type
if predicted_type == 'input':
element.send_keys("Entered Value")
logging.info("Text entered in input field.")
elif predicted_type == 'button':
element.click()
logging.info("Button clicked.")
if __name__ == "__main__":
model, scaler, feature_columns = load_model_and_scaler(MODEL_PATH, FEATURE_COLUMNS_PATH, SCALER_PATH)
driver = webdriver.Chrome()
driver.get("https://training.qaonlinetraining.com/testPage.php")
time.sleep(4)
predict_and_act(driver, model, scaler, feature_columns)
time.sleep(4) # Pause for 2 seconds
print("Execution resumes after 2 seconds.")
driver.quit()
Project Repository
Access the full project and code on GitHub: AI-Powered Automation Testing with TensorFlow
What We Try to Achieve with This Code
The provided code for AI-powered automation testing aims to address common challenges in traditional automation frameworks. Specifically, it achieves the following:
- Dynamic Locator Prediction:
- The code predicts the most reliable locator (
id,class,name, etc.) for identifying web elements, reducing the chances of locator breakage due to UI changes.
- The code predicts the most reliable locator (
- Robust Element Identification:
- By leveraging a trained TensorFlow model, the framework ensures accurate identification of element types (
button,input,link, etc.), even for dynamic and evolving web applications.
- By leveraging a trained TensorFlow model, the framework ensures accurate identification of element types (
- Self-Healing Automation Scripts:
- If a predicted locator fails to identify an element, alternative locators are attempted automatically, improving test script reliability without manual intervention.
- Minimized Maintenance Effort:
- With AI-based predictions, the need for frequent updates to automation scripts is significantly reduced, saving time and effort.
- Scalability:
- The code supports diverse element attributes (e.g.,
id,value,name) and can handle varying datasets, making it adaptable for different projects and environments.
- The code supports diverse element attributes (e.g.,
- End-to-End Automation Workflow:
- Combines AI-based predictions with Selenium to seamlessly locate and interact with web elements, automating testing workflows from start to finish.
- Improved Accuracy and Efficiency:
- Using AI for locator prediction and element type identification enhances the accuracy of test execution while speeding up the overall process.
This code demonstrates how integrating machine learning into automation testing can revolutionize traditional testing methodologies, making them smarter, faster, and more resilient.
Result
Provide Value in Input field
Submit Form










